In this blog post I’ll be sharing some of my recent experiences and thoughts about a rule-based approach to implementing business requirements. In my team (User Account Management, or UAM for short), we have a constant influx of new business requirements regarding how players register, login to their account, what limitations they have when gaming, etc. In essence, we are responsible for the whole player lifecycle alongside a hefty package of jurisdiction-specific requirements. The latter aspect is especially critical, as the failure to properly implement these (legally binding!) requirements could result in fines or even loss of license.
Considering the changing nature of business/legal requirements - as well as the fact that the company is constantly finding new clients and entering into new jurisdictions - there is a common yet fundamental software engineering problem on our hands: how do we introduce changes and include new features into the product whilst retaining a cohesive, easily reasonable and clean(ish) codebase?

No-Bonus Development
Recently, I was involved in a development (we called it “No-Bonus” amongst ourselves) fueled by some specific regulatory requirements mandating that players should only be able to receive gameplay bonuses if certain criteria are met. The conditions were reasonable and standard things: the player needs to be at least X years old, the player must not exceed a certain level of “risk”, a specific time period has to have passed after the last time the player has increased their deposit limits, etc.; nothing ground-breaking or unexpected. After the initial analysis, however, an inevitable question arose: what would be the best way to implement all this? There are, of course, always several options.
The easiest option would be to add some conditionals to the related classes: our beloved if-statements, simple things. For instance, when attempting to give a player some gameplay bonus (be it a manual process by some admin or instigated by an automated system) some internal service calls are to be made in order to obtain the player’s age, risk profile, etc. Now, every programmer knows this to be a non-optimal choice for various reasons:
- What if we need to change the conditions slightly? Or add more? We’d need to do the development, compile, test and deploy the changes. And, as usual, this risks introducing new bugs along the way.
- What if there’s a need for some additional configuration to make sure that the feature only works under a specific jurisdiction?
- What if some clients want a similar feature, but with minor changes to the conditions?
The proposition to do the simplest thing therefore might resemble a strawman, as the listed issues are common and known enough that obviously everyone would try to find a better solution. Yet I’ve seen enough of such approaches in code (let’s be honest, I haven’t just seen, but also created them) to be assured that the lure to add a simple condition or two is real.
A better solution was chosen as expected, one that utilizes an existing feature/subsystem of our product: ACL. ACL (Access Control List) is a kind of a rule engine meant to specify what player actions are permissible/denied in certain situations. It turned out to be the perfect match for the No-Bonus task.
Rule Engine to the Rescue
Business rule engines (sometimes called rules engines), are systems designed to evaluate business rules and act upon the outcome. The rules may be configurable and are often expressed in a DSL (domain specific language), or via a specialized user interface; not just by writing code in source files in a general purpose programming language. The notion of configurability, therefore, entails a key aspect: facilitate changing the rulesets without the need for redeploying. What a great promise!
During the No-Bonus development we added only a few additional usable conditions that any of our clients (not just those concerned about this specific task) could make use of, if they so desired. A great win for reusability, isn’t it? The rules themselves were simple and conveyed the meaning of the requirement in a well-readable manner. For example, a subset of the rules looks similar to this in a configuration UI:
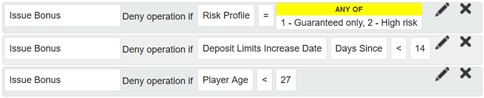
Benefits of the Rules
Given that enough time has passed since the completion of the development – it has passed QA and has been deployed by now – I can easily see some benefits of the chosen approach.
Easy to grasp - A great benefit of the rules is that they can be separate from the program’s source code. This means that people whose day-to-day job does not include programming have an excellent chance of understanding the rules and making informed decisions based on them. This is a huge advantage! Even people who do code may be reluctant to make decisions based on a codebase they are not too familiar with. Of course, there are always the dangers of slightly misunderstanding some abstractions or missing some non-obvious intricacies of the specific area of the codebase. In contrast, if a DSL or a GUI is not clear enough, is misleading or just badly labelled, then it is most likely a bug that needs to be fixed.
Obviously one could argue that the behavior of the system should be documented (at least the business flows) and this is of course a noble goal. However, it is well known that documentation and code does go out of sync more easily than we’d like. Even the slightest dissonance of the documentation and code can result in some sort of awfulness. Configured rules, on the other hand, are ideally self-documenting.
Easy to test - The conditions can be tested in isolation. Moreover, because our ACL has its own API, testing it is not dependent on the business flows that make use of the ACL and as such requires way fewer setup steps and additional assumptions during testing. We all know that misguided assumptions are the main causes of software bugs. This was super helpful not only for me as a developer, but also for QA, who wouldn’t need to replay the whole “user story”-like flow when testing a small change in parameters.
Reduced complexity - Due to the decoupled nature of rules from the rest of the business logic code, another developer can easily introduce changes or add new features to the system without the need to dive deep into subtleties of some other business logic flows that call ACL. In short, a rule engine can greatly reduce the complexity of the system, and consequently reduce bugs.
These observations seem to agree with the benefits Martin Kleppmann has mentioned in “Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems” (2017) about the improved maintainability of a system making use of rule engines:
- Operability – easier for ops teams to monitor, identify and handle hiccups in production due to the confinement of certain types of requirements to a tighter space
- Managing complexity – avoids codebase-degrading special-casing
- Evolvability – adding new conditions should be relatively painless

Keep it Simple, Stupid
Delegating the business requirements to a rule engine can backfire, though. Rules can get overly complex, especially if they have side-effects: the evaluation order starts to matter and rules become non-trivial. So, it becomes vital to give it a KISS.
Martin Fowler has pointed out some useful heuristics to follow to keep the complexity under control. The most useful notion for me was the recommendation to limit the rule engine to purpose by narrowing the context. A system tailored for a confined domain won’t start to live its own life (sentient even?), becoming unreadable due to the (mis-)usages of all the possible features someone has managed to lump together.
Another nuance to be kept in mind affecting how people comprehend the rules (and therefore becomes a measure of complexity) concerns the use of negative conditions. In order to lessen the chance of confusion, try to formulate the possible conditions and the problem in question - in an affirmative manner.
For conditions, i.e. the atoms of a rule, it is fairly self-evident. Consider the following rule that, say, disallows betting:
On bet: DENY if documents [are] unverified.
If we need to negate this rule, however (let’s say, there are some things happening only for player with unverified documents) then it becomes:
On bet: DENY if documents [are not] unverified.
The reason why
it gets more awkward to parse in-the-head is due to the use of a double-negative,
something people frequently struggle with. For example, various natural
languages handle double negatives differently. Even within a single language, they can be interpreted differently depending on
context.
But negatives may creep into the system in a more subtle manner as well. A few years ago my team was working on a GDPR solution that allows us to specify a set of rules denoting the conditions under which the player’s data would be kept in the system. The ruleset is aptly named ‘Data retention policy’ and following the philosophy of personal data protection and GDPR, the idea of not keeping the data indefinitely as a default is natural. So, the rules are there to keep/retain the data, not to remove. However, since the introduction of the system, it has caused a lot of confusion, despite the accompanying guiding text. The reason, I believe, is due to the opposite concerns of the rules and the people working with the rules. For the QA the usual question is: “Does this player get removed from the system if the conditions are correct?”. The analysts and ops are mostly trying to make sure that the system is compliant, but first and foremost: there should be no accidental data loss. Accordingly, they, too, are mostly interested under what conditions a player CAN be forgotten from the system. And just like that, the rules are mostly interpreted in the opposite way, effectively becoming a game of negating the rules all the time. Consider the following simple rule:
A ∧ B ∧ (C ∨ D)
If we are to negate it, then it becomes:
¬(A ∧ B ∧ (C ∨ D))≡¬A ∨ ¬B ∨ (¬C ∧ ¬D)
While understandable, it is not so simple anymore and probably way more likely to cause misunderstandings. It is therefore useful to keep the common use case in mind.
An additional aspect worth mentioning is that which may render a beautifully crafted feature ultimately useless – performance. Indeed, in my case that was paramount as the ACL rules are evaluated for almost all player actions, so expensive database reads must be kept to a minimum. The values of the conditions/player attributes (at least the ones introducing an adverse effect on performance when read from the database) are accessed via read-through cache. Of course, with any sort of caching, the question of cache invalidation comes up and is not to be taken lightly. After all, "there are two hard things in computer science: cache invalidation, naming things, and off-by-one errors.". Fortunately we could make use of the player-to-server assignment mechanism that confines all player related actions (and associated in-memory data) to a specific server, thus providing an effective sharding solution. As the player is logged out or assignment is transferred to another server, all the in-memory data regarding the player – including the cached values needed for the rules – is cleared, therefore providing an easy, yet effective caching strategy without concurrency issues getting in the way. It must be noted that without the guarantees provided by the sharding mechanism, the whole rule-based approach wouldn’t have worked. Truly, a frequent evaluation of whole rulesets without the performance constraints kept in mind would kill the performance and ultimately turn the whole undertaking to folly, no matter how elegantly the abstractions are devised, how masterful the architecture looks on paper or how easy the solution is to sell to the stakeholders.
Business rule engines are a useful tool that can really shine in case of a certain type of problems. They absolutely help in keeping the code base hygiene level under control and in my experience are less prone to bugs than some alternatives in certain situations (although “It’s software. It’s buggy” – Mark Twain, probably). Yet, just like with all software engineering patterns it is to be used judiciously, lest you should end up debugging an entangled mess of conflicting rules in production.
We are also constantly hiring, so be sure to check our careers page and if you recognize yourself in any role, send us your application.